Machine learning models only work with a numeric representation of input data. Suppose we have a training corpus with three sentences:
“the dog saw a cat”,
“the dog chased the cat”,
“the cat climbed a tree”.
The corpus vocabulary has eight words, which are listed alphabetically as follows
index
vocabulary
1
a
2
cat
3
chased
4
climbed
5
dog
6
saw
7
the
8
tree
Tokenization
The different units into which you can break down text are called tokens. The token can be a word (e.g. “cat”), or a phrase (e.g., “the cat”, or “a cat”). Eventually, we will transform each token to a numeric vector.
Code
from tensorflow.keras.preprocessing.text import Tokenizertexts = ["the dog saw a cat","the dog chased the cat","the cat climbed a tree"]tokenizer = Tokenizer()tokenizer.fit_on_texts(texts)sequences = tokenizer.texts_to_sequences(texts)# print("The count of words", tokenizer.word_counts)print("The sequences generated from text are:", sequences)
The sequences generated from text are: [[1, 3, 5, 4, 2], [1, 3, 6, 1, 2], [1, 2, 7, 4, 8]]
The code provides an example of tokenization. It creates tokens for each of the 8 words in the vocabulary and assigns an integer to each token (e.g., “then” = 1 and “dog” = 3). As a result, each sentence is transformed into a sequence of numbers.
One-hot encoding
One-hot encoding is the most common, most basic way to turn a token into a vector. It is a binary vector of the size of the vocabulary where the vector has 1 for the index of the word, and 0 elsewhere. For example, “cat” has index 2 in the alphabetical order of the vocabulary. Then, the one-hot encoding of the word “cat” can be \underbrace{[0,1,0,0,0,0,0,0]}_{8} and, the sentence “the dog saw a cat” can be represented as a 5 \times 8 matrix
since the sentence has 5 words and the corpus vocabulary has 8 words. recall that this is exactly how we reshaped labels when using ConvNet for MNIST data.
One-hot encoding has two drawbacks for natural language processing (NLP) tasks:
The dimensionality of the vector space becomes very high and sparse because each vector has the size of the vocabulary.
There is no connection between words with similar meanings. For example, it is impossible to know that “dog” and “cat” are both pets.
Frequency Encoding
One-hot encoding is a binary vector of the size of the vocabulary where the vector is all zeros, but has 1 for the index of the word. We can also encode the sentence based on the frequency of each word’s occurrence. Then, the sentence “the dog saw a cat” becomes an array
[4, 2, 1, 2, 3]
However, similar to one-hot encoding, this frequency-based encoding does not capture any relationships between words with similar meanings. Even worse, in our example, “dog” and “a” have the same frequency, making them indistinguishable from each other.
Embedding
Word embeddings are a popular and powerful way to represent words as vectors. These word vectors capture the semantic meaning of words, allowing for more effective processing in natural language processing (NLP) tasks.
Given input texts, a word embedding model constructs a numeric vector for each word, transforming the text into a numerical representation. Initially, words are often represented using basic methods like one-hot encoding. These vectors are then passed through an embedding model. This model, built from large corpora of text, functions as a complex mathematical system that performs extensive calculations to generate more informative word vectors. These vectors position words with similar meanings close to each other in the vector space, effectively capturing their semantic relationships.
Word embeddings are foundational in NLP, enabling advanced applications such as sentiment analysis, machine translation, and more. By capturing the nuances of language, word embeddings significantly enhance the performance of machine learning models in understanding and generating human language.
Next, we will use a popular pre-trained embedding model, word2vec, to see how we can perform various operations with these vectors.
In word2vec, each word is converted into a vector of numbers. For example, the word “university” might be represented as a 300-dimensional vector, meaning it has 300 numbers associated with it. These numbers capture various aspects of the word’s meaning and context. The example below shows the first 4 numbers in the vector.
One of the cool things about word embeddings is that we can measure how similar two words are by looking at the distance between their vectors. Words with similar meanings will have vectors that are close to each other.
For instance, using the word2vec model, we can find the top 3 words most similar to “university” are: “universities”, “faculty”, “undergraduate”. The number after each word quantifies the probability of the similarity.
Word embeddings can also help us find a word that doesn’t fit in a list of words. For example, given the list [“apple,” “banana,” “car,” “orange”], the word “car” would be identified as the odd one out because it is not a fruit.
Another interesting feature of word embeddings is that we can perform mathematical operations with the vectors to find relationships between words. Here are two examples:
Word Analogy: “woman” + “king” - “man” = “queen”
This operation finds that the relationship between “woman” and “man” is similar to the relationship between “queen” and “king.”
Word embeddings like word2vec provide a powerful way to represent words and their meanings in a numerical form. This allows us to perform various operations to understand word relationships, find similarities, and even solve word analogies. These capabilities make word embeddings an essential tool in natural language processing and machine learning.
Applications
Sentiment Analysis of IMDB Movie Reviews
The IMDB dataset is a commonly used dataset for machine learning tutorials related to text and language. It contains 50,000 movie reviews, with 25,000 in the training set and 25,000 in the testing set, collected from IMDB. Each review in the dataset has been labeled with a binary sentiment: positive (1) or negative (0). The following code loads the IMDB data:
The following code snippet shows the 11th to 15th words in the dictionary of this dataset:
Code
from keras.datasets import imdbmax_features =10000(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)word_index = imdb.get_word_index()reverse_word_index =dict([(value, key) for (key, value) in word_index.items()])print("Example of dictionary:\n", dict(sorted(reverse_word_index.items())[10:15]))
Example of dictionary:
{11: 'this', 12: 'that', 13: 'was', 14: 'as', 15: 'for'}
The raw data contains the text of each movie review. The following code snippet shows the first review in the training data, which contains 218 words and has a positive sentiment:
Code
def show_review(index): decoded_review =' '.join([reverse_word_index.get(i -3, '?') for i in x_train[index]])print('Review:', decoded_review)print('\n')print('Number of words:{}'.format(len(decoded_review.split())))print('\nsentiment:', y_train[0])# print('Indices for all ?s:', [x_train[index][i] for i, w in enumerate(decoded_review.split()) if w == '?'])show_review(0)# print("Decode review x_train[0][:10]]:\n",# ' '.join([reverse_word_index.get(i - 3, '?') for i in x_train[0][:10]]))
Review: ? this film was just brilliant casting location scenery story direction everyone’s really suited the part they played and you could just imagine being there robert ? is an amazing actor and now the same being director ? father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for ? and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also ? to the two little boy’s that played the ? of norman and paul they were just brilliant children are often left out of the ? list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don’t you think the whole story was so lovely because it was true and was someone’s life after all that was shared with us all
Number of words:218
sentiment: 1
Next, we ask AI to help perform some basic exploratory data analysis.
Prompt
Using the IMDB dataset in Keras, we generate key statistics for both the training and test datasets. These statistics include:
Number of reviews
Proportion of positive reviews
Proportion of negative reviews
Number of words in positive reviews (show min/max/median)
Number of words in negative reviews (show min/max/median)
Creates a table with one column for the training data and another column for the test data.
Code
import numpy as npimport pandas as pdfrom tensorflow.keras.datasets import imdb# Load the IMDB dataset(train_data, train_labels), (test_data, test_labels) = imdb.load_data()# Calculate key statistics for the training datanum_train_reviews =len(train_data)num_test_reviews =len(test_data)# Proportions of positive and negative reviewsproportion_positive_train = np.sum(train_labels) / num_train_reviewsproportion_negative_train =1- proportion_positive_trainproportion_positive_test = np.sum(test_labels) / num_test_reviewsproportion_negative_test =1- proportion_positive_test# Number of words in positive/negative reviewsdef word_counts(data, labels, positive=True):return [len(review) for review, label inzip(data, labels) if label == positive]train_data_positive = word_counts(train_data, train_labels, positive=True)train_data_negative = word_counts(train_data, train_labels, positive=False)test_data_positive = word_counts(test_data, test_labels, positive=True)test_data_negative = word_counts(test_data, test_labels, positive=False)# Calculate min, median, maxdef min_median_max(word_counts):return np.min(word_counts), np.median(word_counts), np.max(word_counts)min_words_positive_train, median_words_positive_train, max_words_positive_train = min_median_max(train_data_positive)min_words_negative_train, median_words_negative_train, max_words_negative_train = min_median_max(train_data_negative)min_words_positive_test, median_words_positive_test, max_words_positive_test = min_median_max(test_data_positive)min_words_negative_test, median_words_negative_test, max_words_negative_test = min_median_max(test_data_negative)# Resultsdata = {"Statistics": ["Number of reviews", "Proportion of positive reviews", "Proportion of negative reviews","Number of words in positive reviews (Min)", "Number of words in positive reviews (Median)", "Number of words in positive reviews (Max)","Number of words in negative reviews (Min)", "Number of words in negative reviews (Median)", "Number of words in negative reviews (Max)" ],"Train set": [ num_train_reviews, proportion_positive_train, proportion_negative_train, min_words_positive_train, median_words_positive_train, max_words_positive_train, min_words_negative_train, median_words_negative_train, max_words_negative_train ],"Test set": [ num_test_reviews, proportion_positive_test, proportion_negative_test, min_words_positive_test, median_words_positive_test, max_words_positive_test, min_words_negative_test, median_words_negative_test, max_words_negative_test ]}# Create a DataFramedf = pd.DataFrame(data)# Display the DataFramedf
Statistics
Train set
Test set
0
Number of reviews
25000.0
25000.0
1
Proportion of positive reviews
0.5
0.5
2
Proportion of negative reviews
0.5
0.5
3
Number of words in positive reviews (Min)
13.0
10.0
4
Number of words in positive reviews (Median)
178.0
172.0
5
Number of words in positive reviews (Max)
2494.0
2315.0
6
Number of words in negative reviews (Min)
11.0
7.0
7
Number of words in negative reviews (Median)
179.0
176.0
8
Number of words in negative reviews (Max)
1571.0
1095.0
The reviews are equally split between positive and negative reviews for both sets. We can see some differences between positive and negative reviews, especially the minimum and maximum number of words per review. Besides understanding the dataset, the reason for looking at some of these key summary statistics is to determine whether we can engineer certain numeric features and build a simple logistic regression or tree-based classifier for sentiment analysis.
Prompt
Generate histogram of word count per review for positive sentiment and negative sentiment in the training data.
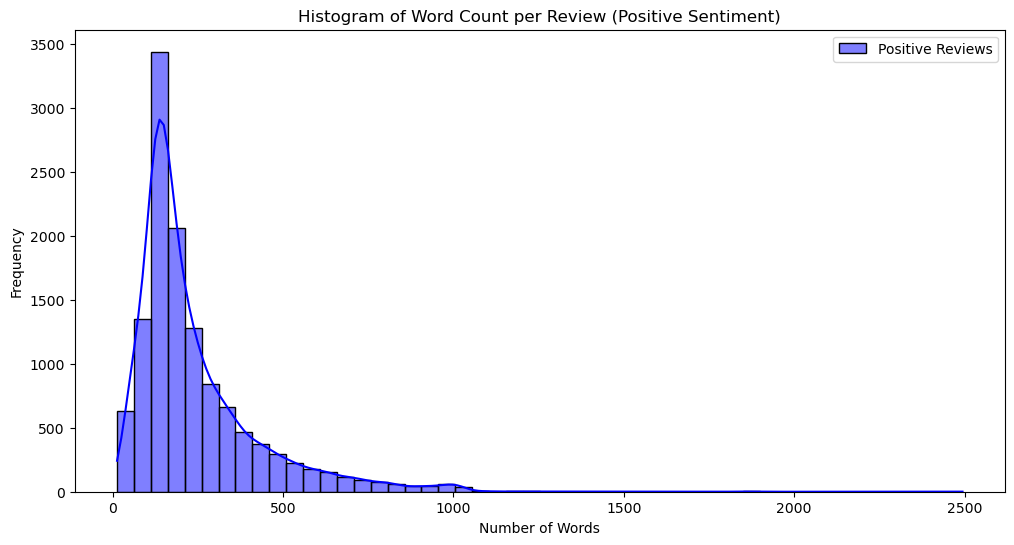
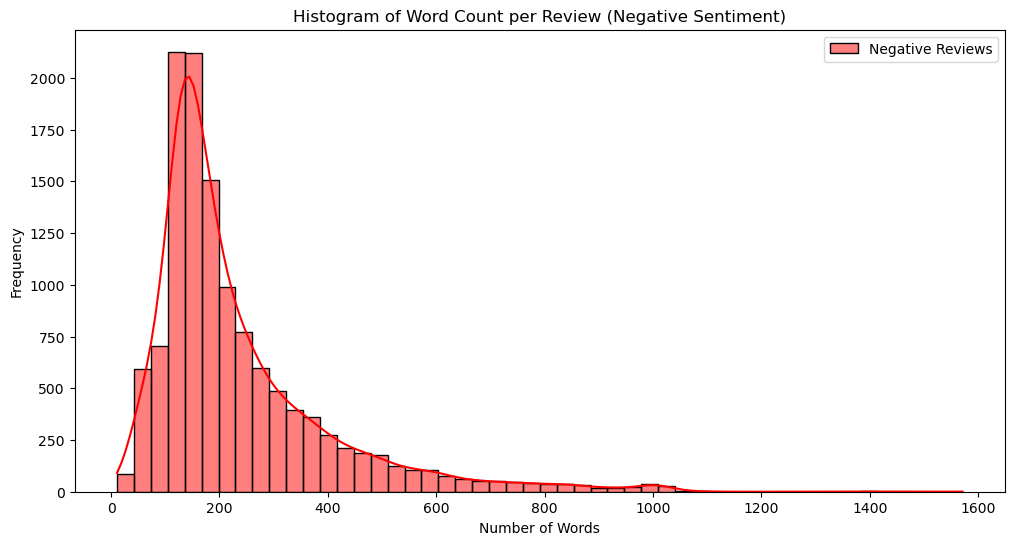
In that vein, let’s examine the distribution of the number of words per review, comparing positive and negative sentiments. Are there any differences in the number of words for positive and negative reviews? And if so, are negative reviews usually longer or shorter than positive reviews? We can answer these questions by looking at Figure 1.
Code
import numpy as npfrom tensorflow.keras.datasets import imdbimport matplotlib.pyplot as pltimport seaborn as sns# Load the IMDB dataset(train_data, train_labels), _ = imdb.load_data()# Function to get word countsdef word_counts(data, labels, positive=True):return [len(review) for review, label inzip(data, labels) if label == positive]# Get word counts for positive and negative reviewstrain_data_positive = word_counts(train_data, train_labels, positive=True)train_data_negative = word_counts(train_data, train_labels, positive=False)# Plot histogram for positive reviewsplt.figure(figsize=(12, 6))sns.histplot(train_data_positive, bins=50, kde=True, color='blue', label='Positive Reviews')plt.xlabel('Number of Words')plt.ylabel('Frequency')plt.title('Histogram of Word Count per Review (Positive Sentiment)')plt.legend()plt.show()# Plot histogram for negative reviewsplt.figure(figsize=(12, 6))sns.histplot(train_data_negative, bins=50, kde=True, color='red', label='Negative Reviews')plt.xlabel('Number of Words')plt.ylabel('Frequency')plt.title('Histogram of Word Count per Review (Negative Sentiment)')plt.legend()plt.show()
(a) positive sentiment
(b) negative sentiment
Figure 1: Historgram of words count
In Figure 1, we can see no significant differences between positive and negative reviews in terms of the number of words. Therefore, the number of words in a review does not accurately predict whether the review is positive or negative.
Next, we will build a neural network model. Before training a machine learning model, the dataset needs to be preprocessed. This includes removing frequently occurring words that do not contribute much to the meaning of the text, such as stopwords like “the,” “and,” or “a.” Additionally, most machine learning algorithms require the same number of features, i.e., the same length for each review.
To achieve this, the pad_sequences function sets the maximum number of words in each review (maxlen):
For reviews that have fewer than maxlen words, the above code pads them with “0” For reviews that have more than maxlen words, the code truncates them.
Code
import kerasfrom keras.datasets import imdbfrom keras import models, layersfrom keras.utils import pad_sequencesfrom keras import backend as Kmax_features =10000maxlen =20(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)x_train = pad_sequences(x_train, maxlen=maxlen)x_test = pad_sequences(x_test, maxlen=maxlen)model = models.Sequential()model.add(layers.Embedding(input_dim=max_features, output_dim=8))model.add(layers.Flatten())model.add(layers.Dense(1, activation='sigmoid'))model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2, verbose=0)# show model summarymodel.summary()# show fitting information# vars(history)# # Create a Keras model with input and all layers' output# layer_outputs = [layer.output for layer in model.layers]# model_with_output = keras.Model(inputs=model.inputs, outputs=layer_outputs)# # Compute the outputs of all layers for the input tensor# outputs = model_with_output(x_train)# weights = [layer.get_weights() for layer in model.layers]# Evaluate the model on test datatest_loss, test_acc = model.evaluate(x_test, y_test)print(f"Test accuracy: {test_acc:.4f}")
This very simple model achieves an accuracy of 0.75, meaning it correctly predicts the sentiment of 75% of the test data. There are many ways to improve the model using advanced techniques such as RNN (Recurrent Neural Networks), LSTM (Long Short-Term Memory), GRU (Gated Recurrent Units), or Transformers, which is the most popular architecture used in many AI models today.
Transformers have revolutionized the field of natural language processing (NLP). They use a mechanism called self-attention to process and generate sequences of words, allowing them to handle long-range dependencies in text more effectively than RNNs and LSTMs. Transformers are the backbone of many state-of-the-art models, such as BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), which have achieved remarkable results in various NLP tasks.
Recommendation System
Next, we will demonstrate a cool application of embeddings to create a recommendation system. The retail data used to train our model contains the following information:
Upload the data to ChatGPT, and AI can be utilized to generate the summary statistics of the dataset.
Prompt
Show a few rows of the data and generate summary statistics for each column, including measures such as count, mean, standard deviation, minimum, and maximum values.
We will collect the products purchased by each customer (identified by CustomerID). Our goal is to build a model that understands why customers buy certain products together. Once the model is trained, it can recommend products to future customers based on what it has learned about customer behavior. To do this, we will randomly select 90% of the customers for training and 10% for testing.
Both the training and testing data will be in the form of lists of lists, like this: [[a1, a2], [b1, b2, b3], …], where a1 and a2 are StockCode in the data (or products) bought by one customer, and b1, b2, and b3 are products bought by another customer, and so on.
In our model, we treat a1, a2, b1, b2, b3, etc., as words, and [a1, a2], [b1, b2, b3] as sentences. In language, the meaning of individual words can be unclear, but sentences give more context and clarity. Similarly, it is difficult to understand a customer’s behavior from a single product, but by looking at a list of products they bought together, we get a clearer picture of their preferences. Therefore, we use word embedding to convert each StockCode (product) into vectors. We again use the popular pre-trained embedding model, Word2Vec, for our task.
Code
import pandas as pdimport randomfrom gensim.models import Word2Vec# Load the dataset with correct data typesfile_path = base_url +"/data/retail.csv"data = pd.read_csv(file_path, dtype={'CustomerID': str}, parse_dates=['InvoiceDate'])# Shuffle customers and split into training and testing setscustomers = data.CustomerID.unique().tolist()random.shuffle(customers)split_point =round(0.9*len(customers))customers_train = customers[:split_point]customers_test = customers[split_point:]# List to capture purchase history of the customerstrain_data = []longest =0# Populate the list with the product codes for training datafor customer in customers_train: purchase_history = data[data["CustomerID"] == customer]["StockCode"].tolist()iflen(purchase_history) > longest: longest =len(purchase_history) train_data.append(purchase_history)# Train Word2Vec modelmodel = Word2Vec(sentences=train_data, vector_size=100, window=longest, min_count=1, workers=4)
After the model is trained, here’s an example showing how one of the products is converted into a vector:
Since the target product is a birthday card, the model finds that greeting cards have the highest similarity. This is quite amazing, considering that the training data we fed into the model is simply the StockCode, which to us (humans) has no inherent meaning. The model learns the relationships between products purely through the sets of StockCodes that are purchased together.
With this embedding model, we can build a recommendation system. For a basic example, we can predict the next purchase based on a given purchase history. The example shows that for a customer in the testing data, we use his/her purchase history to predict the next purchase.
Code
# Example: Predicting products for a given purchase historydef predict_next_purchase(purchase_history):# Use the model to predict the next likely product, excluding the product itself vector = model.wv[purchase_history] similar_products = model.wv.most_similar(positive=vector, topn=10)for product, similarity in similar_products:if product notin purchase_history:return productreturnNone# Predicting the next product for the first customer in the test settest_customer_index =1first_product = test_data[test_customer_index][0]first_description = data[data['StockCode']==first_product]['Description'].values[0]first_test_customer_history = test_data[test_customer_index]predicted_product = predict_next_purchase(first_product)# Show the product description for the predicted productpredicted_description = data[data['StockCode'] == predicted_product]['Description'].values[0]# Check if the predicted product was actually purchased by the customeractual_purchase = predicted_product in first_test_customer_historyprint(f"For customerID = {customers_test[test_customer_index]}")print(f"The first purchased product is StockCode={first_product} (Description: {first_description})")print(f"Predicted product is StockCode={predicted_product} (Description: {predicted_description})")print(f"Was the predicted product actually purchased by the customer? {'Yes'if actual_purchase else'No'}")
For customerID = 13261
The first purchased product is StockCode=48129 (Description: doormat topiary)
Predicted product is StockCode=48188 (Description: doormat welcome puppies)
Was the predicted product actually purchased by the customer? Yes
It is certainly debatable if this is the best logic to use for recommendations. It is also worth noting that this model is probably too simplistic to be deployed in a real-world scenario, especially considering that we only trained the model for about 10 minutes. Nevertheless, this example effectively demonstrates the application of embeddings, and many recommendation systems in real businesses are indeed built using embedding methods.